Sagnik Majumder
|
I am a researcher at Google XR, where I develop computer vision models for video understanding in AR/VR applications. I completed my PhD in Computer Science at UT Austin, advised by Prof. Kristen Grauman. I am broadly interested in computer vision and machine learning. My current line of research is multi-modal understanding of 3D scenes and videos, with applications in mobile robotics and AR/VR. Previously, I worked with Prof. Visvanathan Ramesh at Goethe University on continual and meta learning for image recognition tasks. I also had the pleasure of collaborating with Prof. Christoph Malsburg at the Frankfurt Institute for Advanced Studies for investigating visual models that draw motivation from Neuroscience. Earlier, I graduated from BITS Pilani. Research collaborations: I am open to collaborating on research projects. Shoot me an email to discuss more. CV | Research statement | E-Mail | Google Scholar | Github |

|
|
|

|

|

|

|

|

|
| Google XR 2026-? |
UT Austin 2019-2026 |
Apple AI Summer 2025 |
Meta AI 2022-2024 |
Goethe University / FIAS 2017-2019 |
BITS Pilani 2014-2018 |
|
|
| April 2026 | Joined Google XR full time. |
| March 2026 | Defended my PhD! |
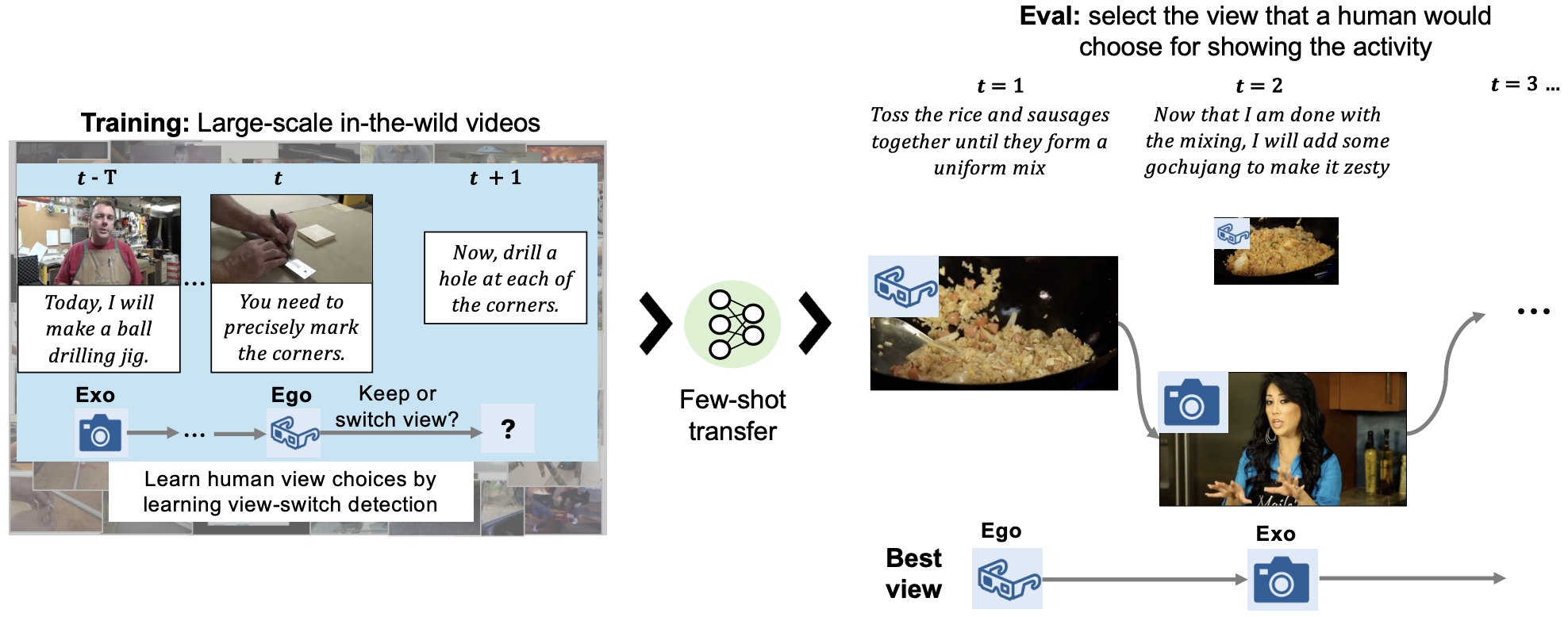
| Oct 2025 | Invited talk at BinEgo-360° and SAUAFG workshop and invited paper presentation at CLVL workshop at ICCV 25 on "Learning Camera View Selection in Instructional Videos". |
| Aug 2025 | Invited talk at Research Summit on Egocentric Perception with Project Aria on "Skill Learning from Instructional Videos". |
| June 2025 | Switch-a-View is accepted at ICCV 25. |
| June 2025 | Joined Apple Computer Vision as a research intern this summer. |
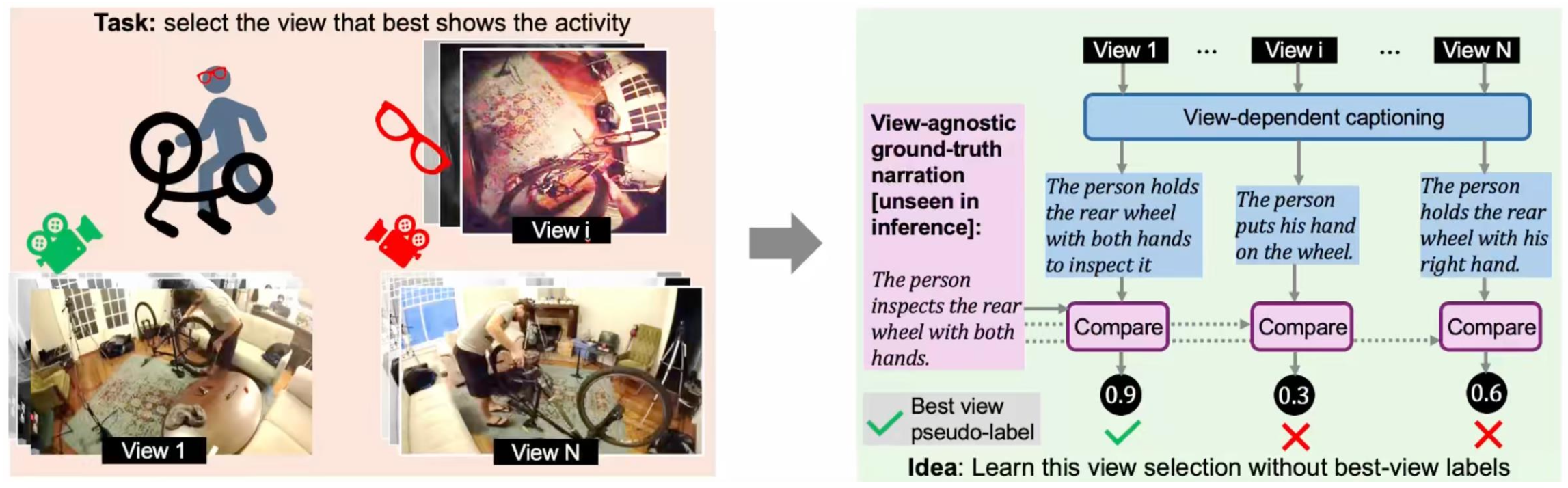
| June 2025 | Invited presentation at EgoVis workshop at CVPR on "Which Viewpoint Shows it Best? Language for Weakly Supervising View Selection in Multi-view Videos". |
| May 2025 | Recognized as an Outstanding Reviewer for CVPR 2025. |
| Apr 2025 | Passed my PhD proposal. Officially a candidate now! |
| Apr 2025 | LangView is accepted as Highlight at CVPR 25. |
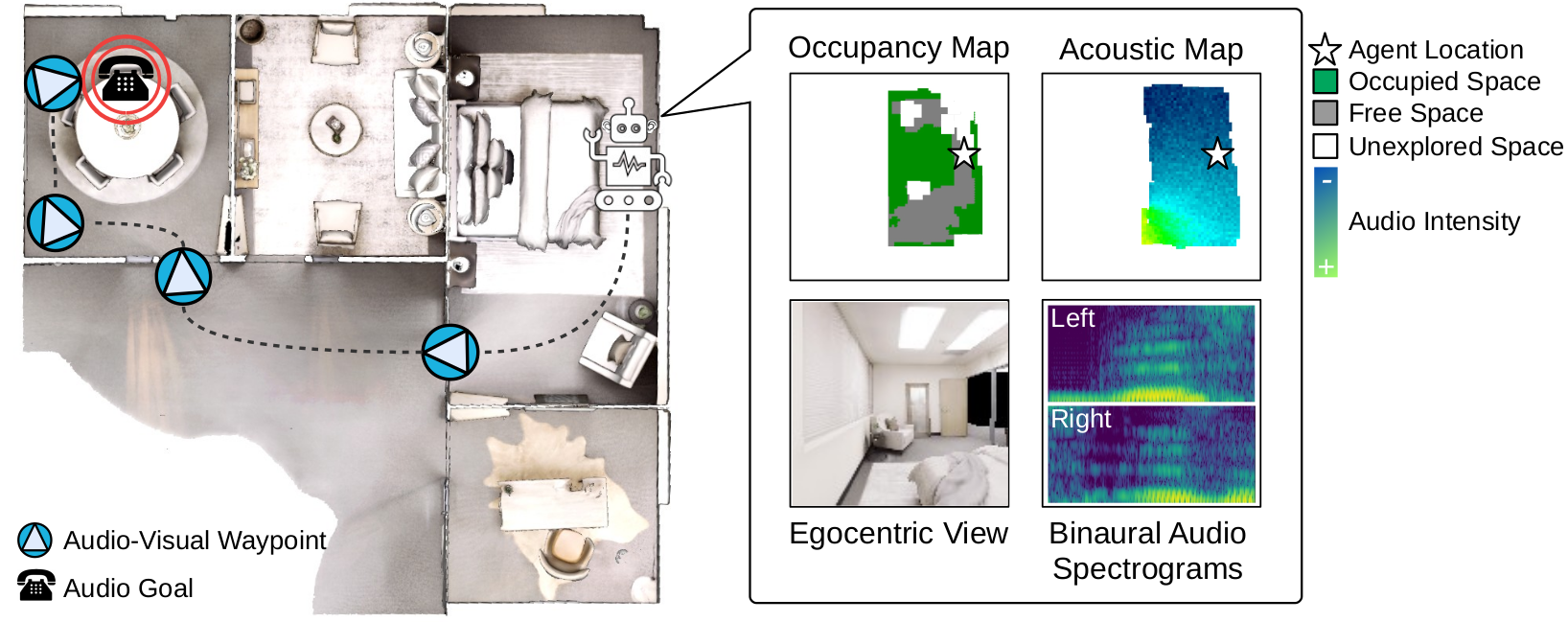
| July 2024 | ActiveRIR is accepted as Oral at IROS 24. |
| June 2024 | Invited talks at Sight and Sound and EgoVis workshops at CVPR on "Learning Spatial Features from Audio-Visual Correspondence in Egocentric Videos". |
| May 2024 | ActiveRIR is covered by TechXplore. |
| May 2024 | Ego-Exo4D is accepted as Oral (0.8% selection rate) at CVPR 24. |
| Mar 2024 | Two papers, Learning Spatial Features from Audio-Visual Correspondence in Egocentric Videos and Ego-Exo4D got accepted at CVPR 24. |
| June 2023 | Invited talk at CVPR 23 Sight and Sound Workshop on "Chat2Map: Efficient Scene Mapping from Multi-Ego Conversations". |
| May 2023 | Invited talk at JHU NSA Lab on "Efficiently understanding 3D scenes using sight and sound". |
| Mar 2023 | Our paper Chat2Map: Efficient Scene Mapping from Multi-Ego Conversations. got accepted at CVPR 23. |
| Feb 2023 | Co-organzing the CVPR 2023 SoundSpaces Challenge and the Embodied AI Workshop. |
| Dec 2022 | Starting as a visiting researcher at Meta AI Research. |
| Oct 2022 | Invited talk at ECCV 22 AV4D Workshop on "Active Audio-Visual Separation of Dynamic Sound Sources". |
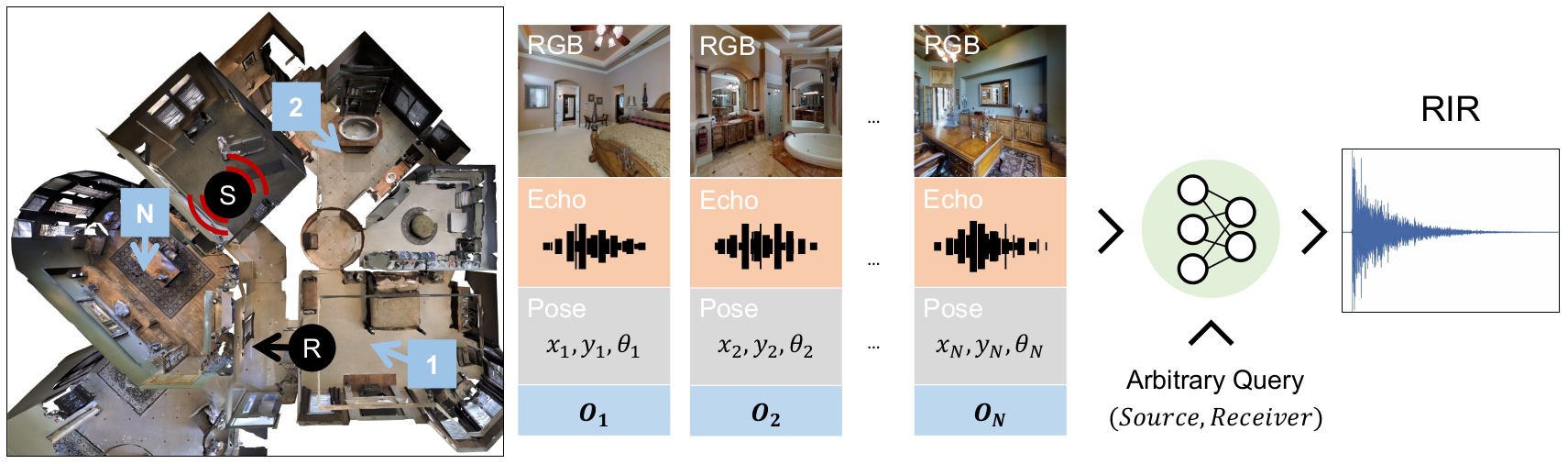
| Sept 2022 | Our paper Few-Shot Audio-Visual Learning of Environment Acoustics got accepted at NeurIPS 22. |
| Sept 2022 | Continuing as a student researcher at Meta Reality Labs Redmond this Fall. |
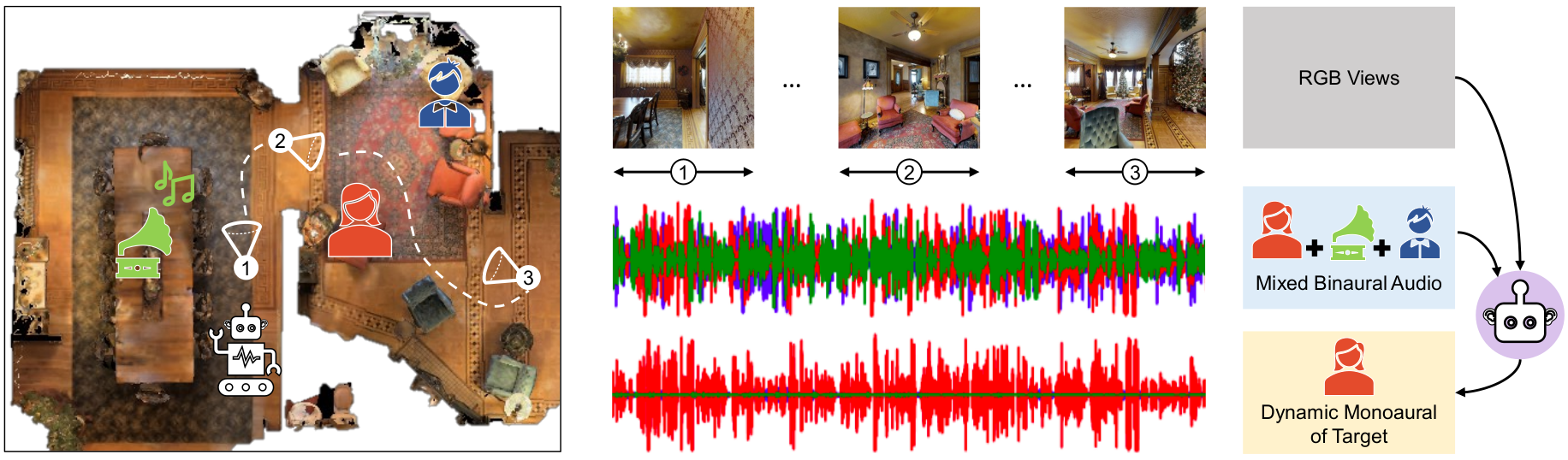
| July 2022 | Our paper Active Audio-Visual Separation of Dynamic Sound Sources got accepted at ECCV 22. |
| June 2022 | Invited talk at CVPR 22 Sight and Sound Workshop on "Active Audio-Visual Separation of Dynamic Sound Sources" (Slides). |
| June 2022 | Joined Meta Reality Labs Redmond as a research scientist intern this summer. |
| April 2022 | Invited talk at Meta AI Research on "Active Audio-Visual Separation of Dynamic Sound Sources" (Slides). |
| Feb 2022 | Co-organzing the SoundSpaces Challenge at the CVPR 2022 Embodied AI Workshop. |
|
|
 |
|
 |
|
 |
|
 |
|
 |
|
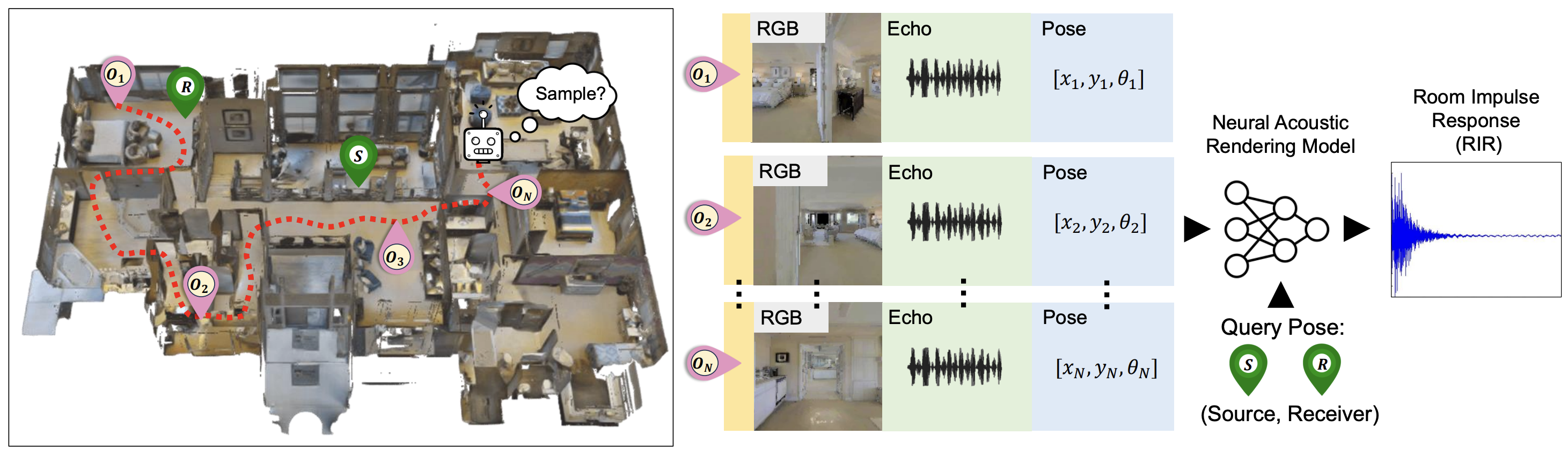 |
|
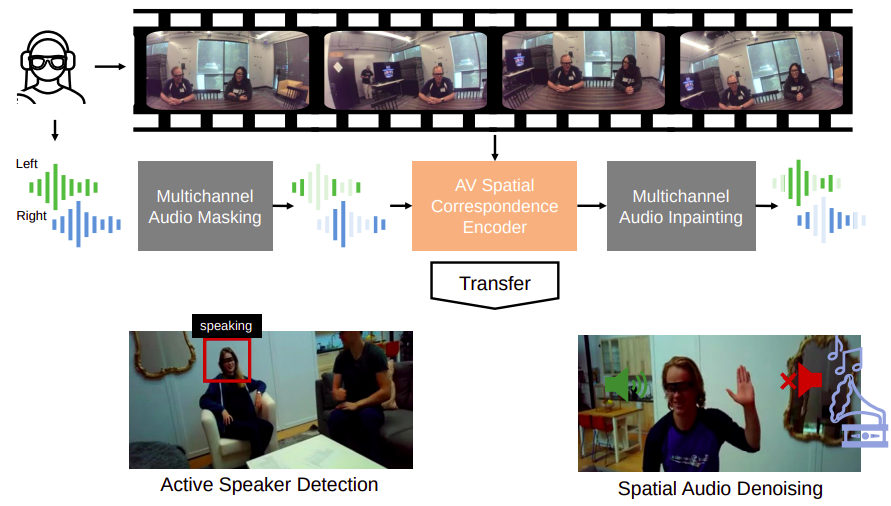 |
|
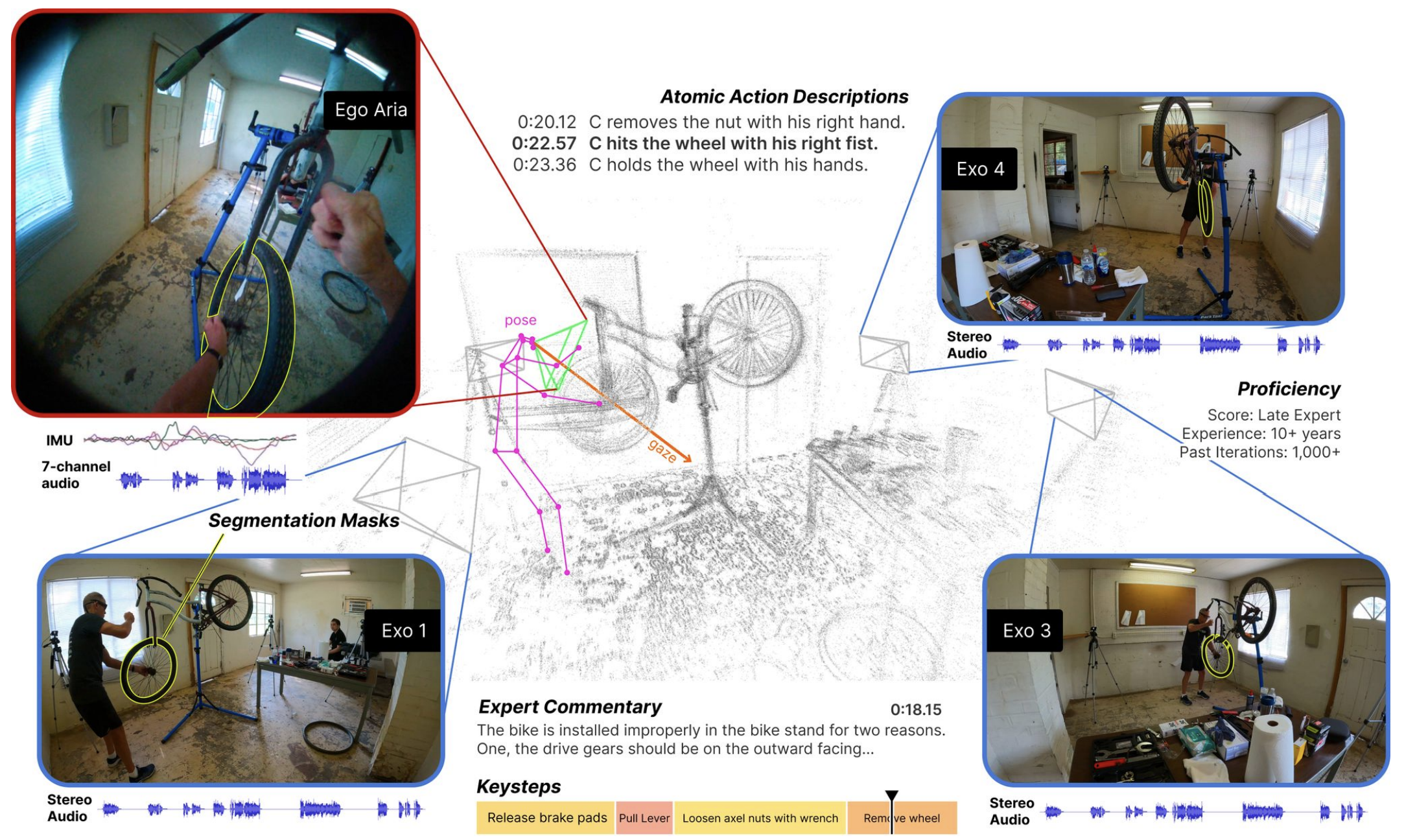 |
|
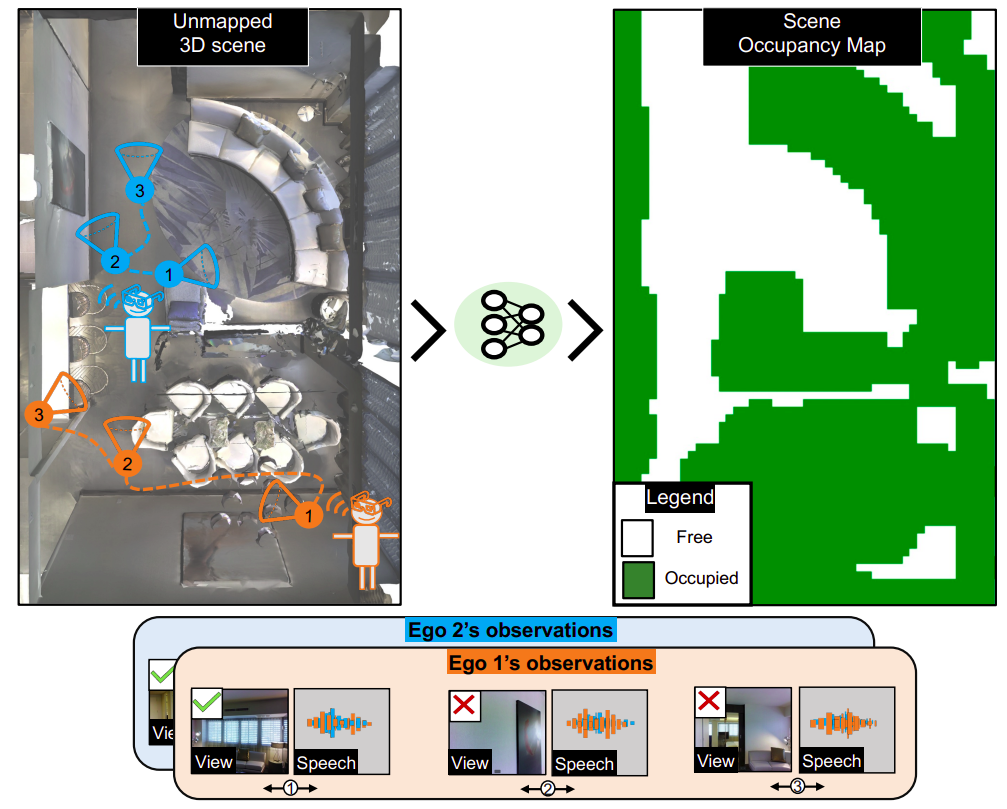 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
![[NEW]](images/new.png)